

7 月 5 日,Meet AI Compiler 技术沙龙第 7 期在北京圆满落幕,既有来自产业界的专家分享最新进展及实战、落地经验,也有来自高校的研究学者详解创新技术的实现路径及优势。
其中,TileAI 社区发起人王磊博士以「Bridge Programmability and Performance in Modern AI Workloads」为题,深入浅出地介绍了创新的算子编程语言 TileLang,分享其核心设计理念与技术优势。
TileLang 旨在提升 AI kernel 编程的效率,将调度空间(包括线程 Binding 、 Layout 、 Tensorize 和 Pipeline)与数据流解耦,并将其封装为一组可自定义的注解和原语。这一方法使用户能够专注于 kernel 的数据流本身,而将大多数其他优化工作交由编译器完成。
评估结果表明,TileLang 在多个关键 kernel 上可实现业界领先的性能,充分展示了其统一的 Block–Thread 编程范式和透明的调度能力,能够为现代 AI 系统开发提供所需的性能与灵活性。
HyperAI 超神经在不违原意的前提下,对演讲分享进行了整理汇总,以下为演讲实录。
关注微信公众号「HyperAI 超神经」,后台回复关键字「0705 AI 编译器」,即可获取确认授权的讲师演讲 PPT 。
为什么需要「新 DSL」
本次分享主要为大家介绍我们团队于 2025 年 1 月 在 GitHub 上开源的 for AI Workloads 的新 DSL TileLang 。
首先想和大家聊一聊为何需要一个新的 DSL?
从个人角度出发,在我于微软的实习经历中,曾参与了一个名为 BitBLAS 的项目,研究混合精度计算,当时主要是基于 TVM/Tensor IR 来实现,最终也获得了非常好的实验效果。但是我们仍发现其有很多问题,例如难以维护——我针对每一个算子,比如矩阵层的混合精度计算写了 500 行 Schedule Primitives(调度原语),虽然写得比较优雅,但只有我自己能看懂这段调度代码,很难找到别人来维护或是扩展。
此外,我发现基于 Schedule 的这一套 IR 很难去描述新的需求或优化。例如,我做 kernel 就是自己写了 3 个 Schedule Primitive 来辅助优化程序,包括 Flash Attention 、 Linear Attention 等,这些算子基于 Schedule 是很难描述出来的。所以,我当时就认为,如果这个项目要继续 Scale 的话,用 TIR 可能是行不通的,需要其他方案。
那么,为什么不能是 Triton 呢?
我也尝试了 Triton,但是发现其很难自定义高性能 kernel 。举例来看,首先我在写 Dequantize 算子时可能需要控制每个线程的行为,如何在高性能 kernel 上实现每个线程的 Dequantize 还是很讲究的。
其次是如何将 Buffer 缓存到合适的 Memory Scope 。例如,在部分 GPU 上,将数据缓存到寄存器上进行反量化(dequantize),然后再写入 Shared Memory 会更好,而有些则是直接写回 Shared Memory 会更好。但在 Triton 上是很难控制的。
最后,我认为 Triton 的 Index 略显复杂。例如,如果需要将一个 Tile 缓存到 Local,则需要编写下图左侧所示代码,但是在 Tensor IR 上则可以像右侧所示用下标去索引,我觉得后者非常好。
基于此,我发现现有的 DSL 都不能满足我的需求,所以我们想做一个创新的 DSL,支持更多的后端和 Custom 算子,并且获得较好的性能。而面向较好的性能,则需要优化 Tiling 、 Pipeline 等各种各样的设计空间。为此,我们提出了 TileLang 这个项目。
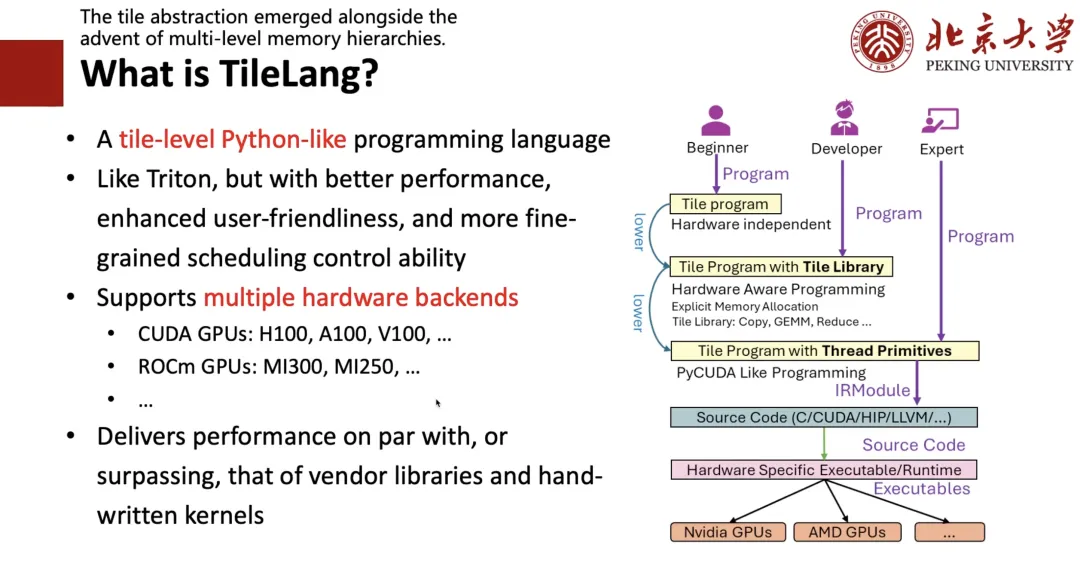
什么是「TileLang」
为什么是「Tile」呢?
首先,我们发现 Tile 这个概念很重要。硬件只要是有 cache 的概念,有寄存器、 Shared Memory,那么在写高性能程序的时候就必须考虑计算分块,也就是 Tile 。 其次,因为考虑到大家都比较写 Python 的程序,所以我们要设计一个 Python-like 的编程语言,要像 Triton 一样好写,并且获得更好的性能。
针对于此,我们设计了如下图右侧所示的框架——如果你是一名专家(Expert),即很懂 CUDA 或是很懂硬件,则可以直接写很底层的代码;如果你是一名开发者(Developer),即会写 Triton 、懂 Tile 、寄存器等概念,则可以像写 Triton 那样去写一个 Tile 级别的程序;如果你是一个完全不懂硬件只懂算法的初学者(Beginner),那你可以像写 TRL 那样写一个高级的表达式,再通过 Auto Schedule 进行 Lower 成对应的代码。
如下图所示,左侧是我用 TIR 写的 Dequant Schedule,可以无缝地等价写成右侧 TileLang 的形式,实现了 Level 1 和 Level 2 共存。

接下来我会介绍一下 TileLang 的设计需要考虑哪些问题。
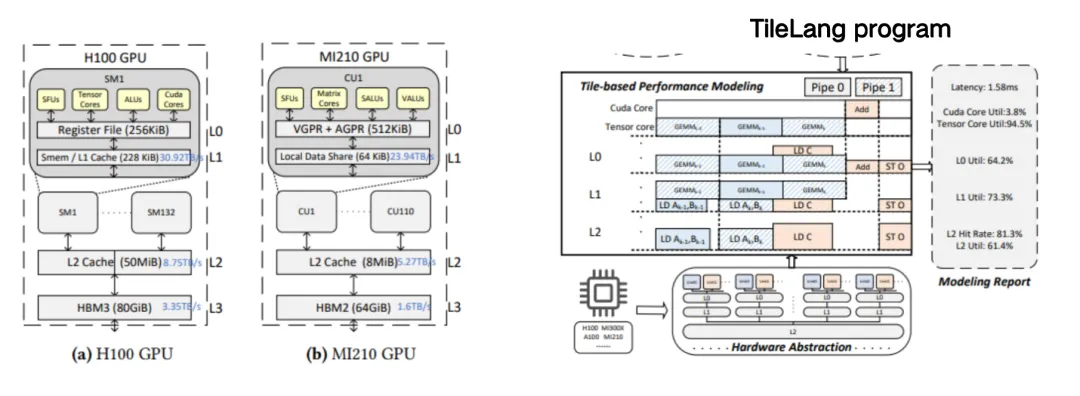
下图左侧是 DeepSeek MLA 的 TileLang 实现,大约有 50 行代码。在这个 kernel 上,我们可以看到,用户需要管理很多事情,例如在启动一个 GPU kernel(核函数)时,需要指定多少个 Block(线程块)来并行执行计算任务,要给每一个 Block 多少线程?这就是我们所说的 Tile Configuration,即下面的每段代码都是有上下文的,用户需要控制 Buffer 在哪个 Memory Scope 上,还需要决定 Shared Memory 或是寄存器的 Layout 是什么样的,还需要去关注 Pipeline 等等。这些都是需要编译器来帮助用户刦管理的。

针对于此,我们将优化空间分为了两类,一类是 Inference,即编译器直接帮助用户推导出较好的方案;一类是 Recommend,即通过推荐选择方案。
综合考虑所有优化空间之后,我们把一个原本由 500 多个代码块构成的高性能 FlashMLA 实现,压缩成了仅 50 行 TileLang 代码,并且保留了 95% 的性能。
下面,我将从 TileLang 的最底层开始为大家进行介绍。
如下图所示,对于 TIR 比较熟悉的同学应该能发现,这就是一个 TIR 表达式。那么,我们基于 TIR 是能够做到 PyCUDA 编程的,例如写两个 Python 的负循环,可以通过 TIR Codegen 成 CUDA 表达式。
如果我们使用 Thread primitives,例如向量化,则可以实现 CUDA 的向量化,从而更进一步地实现线程 binding 。上述都是 TIR 原本都具备的程序,用户就能够像写 CUDA 一样去把程序写出来了,但是用 Python 写的话还是复杂度较高的。
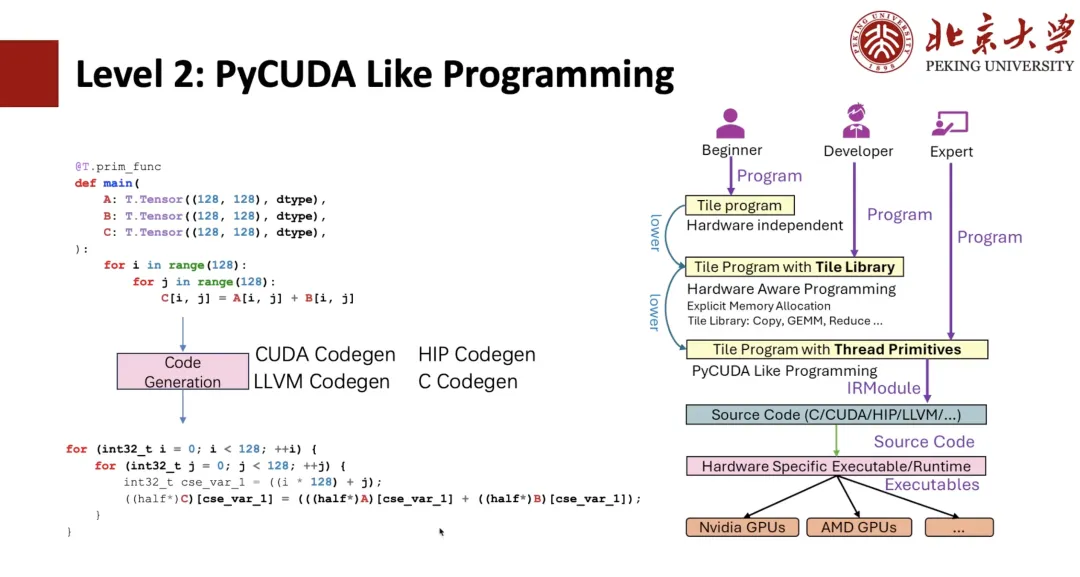
我们为了让用户操作更简便,就提出了 Level 1 Tile Library 的写法。举例来看,我们给定 kernel 上下文 128 个线程,然后将 Copy 用「T.Parallel」包起来,经过编译器的 Inference 就能够推导出刚刚展示的高性能形式,最终 Codegen 成一个 CUDA 代码。如果想更「优雅」一些,可以直接写「T.copy」,直接将 Copy 展开成「T.Parallel」的表达式。
而「T.Parallel」不仅可以做 Copy,还能实现复杂计算,能够自动实现向量化以及线程 Binding 。目前,除了 Copy 之外,我们还提供了 Reduce 、 Fill 、 Clear 等等 Tile Library 的集合。随后,基于 Tile Library 就能够像 Triton 一样写出一个很好的算子。
那么,支持「T.Parallel」的核心概念便是 Memory Layout 。
在 TileLang 中,我们支持使用高级接口对多维数组进行索引,例如 A[i, k] 。这种高级索引最终会通过一系列软件和硬件抽象层被转换为物理 Memory 地址。为了对这一索引转换过程进行建模,我们引入了 Layout,用于描述数据在 Memory 中的组织和映射方式。
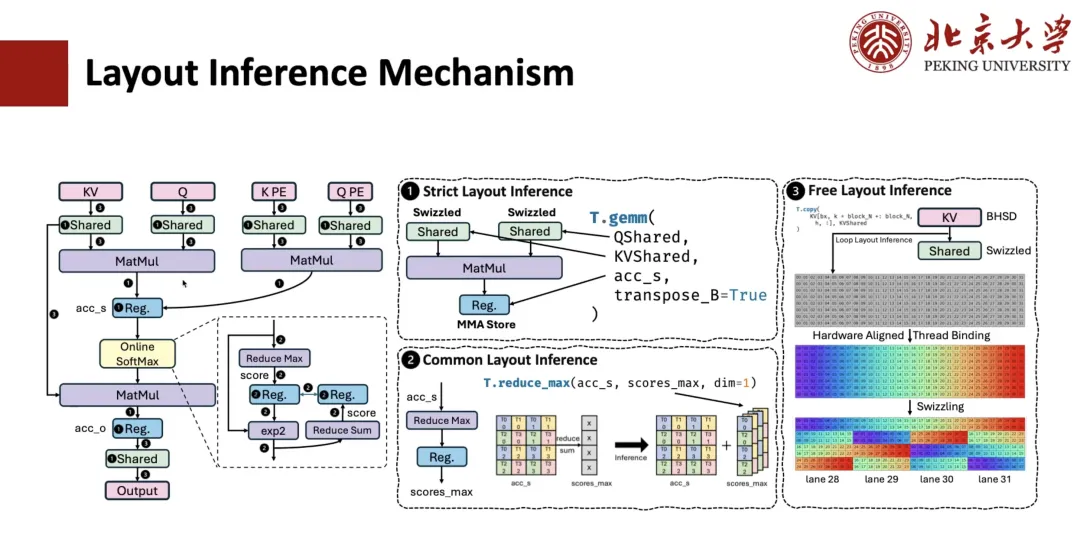
对于 MLA 计算的 Layout 推导是如何实现的呢?通常,这一过程包括 3 个步骤。
第一步是 Strict Layout Inference,比如像矩阵乘这样的算子,对数据 Layout 有很强的约束,必须遵循指定的布局,与其相连的寄存器的 Layout 因此也是确定的。如果涉及 Shared Memory,并且我们知道这个算子需要进行 Spill(寄存器溢出)操作,那么相应的 Memory Layout 也会被确定下来。
第二步是 Common Layout Inference(通用布局推理)。比如,对于与上一步已确定 Layout 相连的表达式,它们的 Layout 也应该是确定的。举例来说,假设我们有一个 accum_s 到 scope_max 的 reduce 操作,其中 QMS 的 Layout 是通过矩阵层指定的,那么我们就可以基于它来推导出 scope_max 的 Layout 。通过这一层的通用推理,大部分中间表达式的 Layout 都可以被确定。
第三步是 Free Layout Inference,即对于剩下的 Free Layout 进行推导,其本身没有被强约束,所以通常会采用一些与与硬件对齐的 Layout Inference 策略,根据访问模式和 Memory Scope,推断出最优的 Layout 方案。
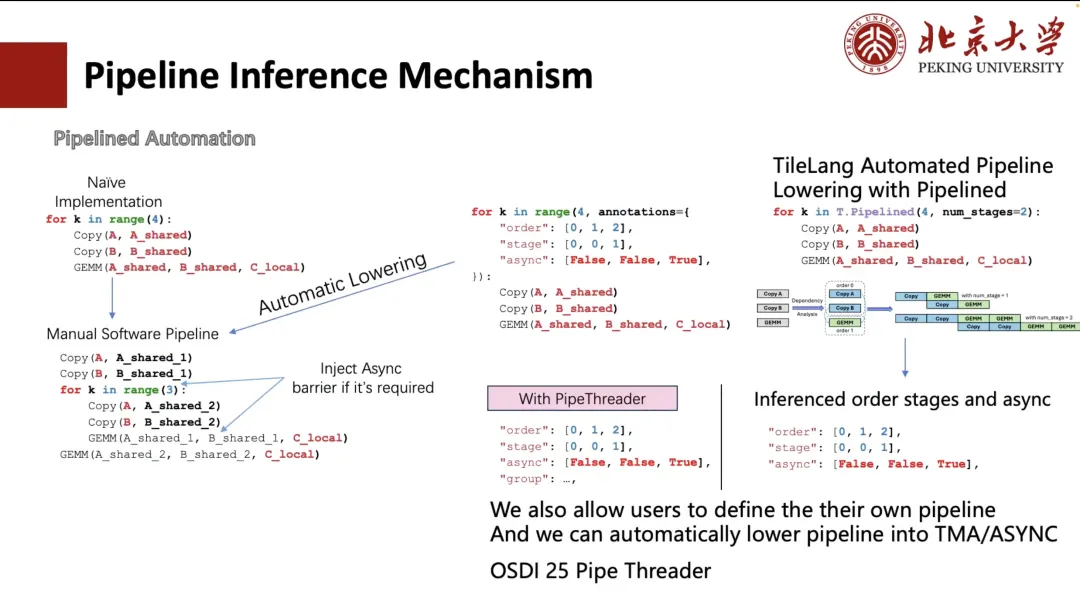
下面介绍一下 Pipeline 是如何做推导的。
一般情况下,我们可以手动展开 Pipeline,但这种写法对用户而言较为繁琐,不够友好。为此,TVM 中曾有工作探索了通过 Annotation 的方式简化该过程。用户只需指定循环的执行顺序(order)和调度阶段(stage),TVM 就可以自动将循环变换为与手动展开等效的结构(如下图中左下角所示)。
但对于用户而言还是比较复杂、麻烦的。所以,在 TileLang 中,我们将其缩减为「num_stage」,用户只需要指定「num_stage」数值,系统就可以自动分析计算中的依赖关系,并据此进行调度划分。在 GPU 或其他多数设备上,实际上只有 Copy 和 GEMM 可以实现真正的异步执行,尤其是 Copy 操作,它可以通过 ASYNC 或 TMA 等机制支持异步传输。
因此,在调度中我们会将 copy 操作单独抽离为一个 Stage,并自动为整个 Pipeline 推导出合适的 Stage 划分。当然,用户也可以选择手动指定调度方式,如左侧图示中的两种自定义排布。
此外,我们还支持基于硬件特性(例如 A100 和 H100 上的 TMA 模块)自动完成 Layout Inference 和调度优化。这部分工作来自我们今年将在 OSDI 25 上发表的项目 Pipe Threader 。
接下来给大家分享关于指令的 Inference 。
以矩阵乘法为例,针对「T.GEMM」可以调用的硬件指令有很多种。例如在 INT8 精度下,可能可以使用 DP4A 指令,或者用基于 TensorCore 的 INT8 实现。而每种指令本身又支持多种 shape,那么在这些实现中,如何选择最优的 Tile 配置就是一个关键问题。
为此,TileLang 提供了两种使用方式:
第一种是 TileLang 可以允许用户可以通过调 PTX 来写 ASM 。但这类方法的缺点是组合空间巨大 —— 如果要兼容全部 PTX,就需要写非常多的代码,同时还需要管理 Layout 。但是这个方法非常自由,我个人也很喜欢该方法。
但我们现在用的是第二种方式,即「T.GEMM」后面用 CUTE/CK-TILE 这种 Tile Library,其提供了矩阵乘常用的 Tile 级别的 Library 接口,但其缺点是由于基于模板展开,编译时间可能非常长。在 RTX 4090 上,编译一个 Flash Attention 可能需要 10 秒,其中 90% 以上的时间都消耗在模板展开上。另一个问题是,它与 Python 前端高度割裂。
所以我们认为,Tile Library 是我们未来会着重发力的一个方向,即通过 Tile 原生的语法支持各种各样的「T.GEMM」和「T.GEMMSP」这一类 Tile 级别的 Library 。
未来工作展望
最后为大家介绍一下我们团队未来的几项工作。
首先是 Tile Sight,其专门用于加速大规模复杂 Kernel(如 FlashAttention 和 FlashMLA)在大语言模型中的性能优化。这是一个轻量级的自动调优框架,旨在为 GPU 、 CPU 和加速器等多种后端生成和评估高效的 Tile 配置(即 tiling 策略或调度提示),帮助开发者快速找到性能优越的调度策略,减少手动调优时间。
基于上述的 custom model,用户就更加容易地去写一个很难的 kernel,例如 MLA,custom model 能够指导用户将每次 cache 放到对应的 shared 上。
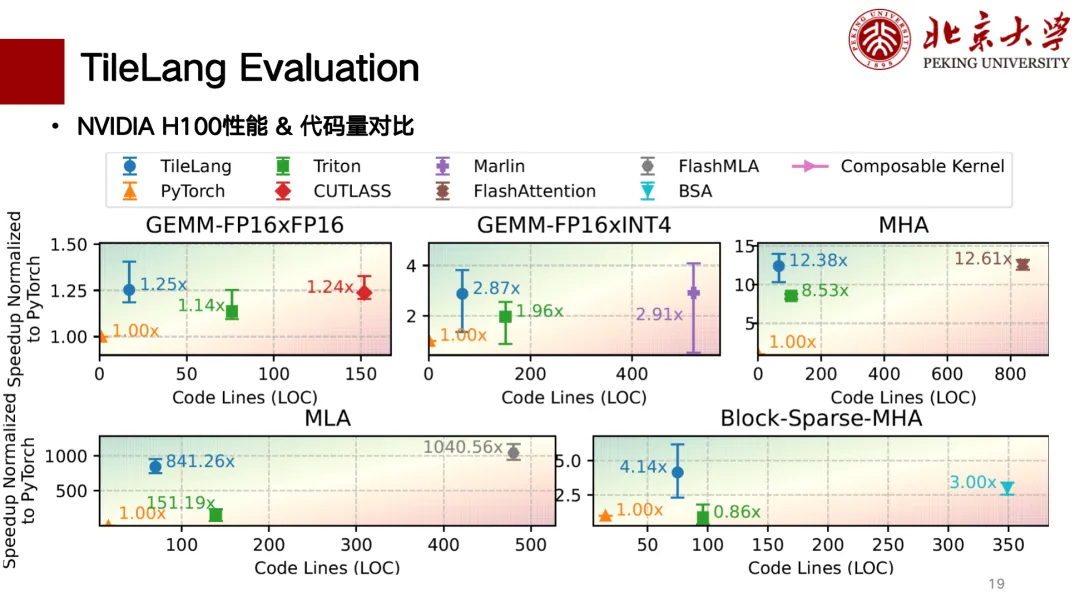
下面是 TileLang 的部分性能评测,我们现在主要完成了 H 卡和 A 卡的支持,下图是代码行数和性能的关联对比图,越往左上角的性能越好。其中,对于矩阵乘而言, TileLang 可以获得与 CUTLASS 相近的性能。此外,像 MLA 、 Flash Attention 、 Block Sparse 等算子也可以获得和 CUTLASS 相似的性能,同时代码行数也相对较少,写起来也是比较「clean」的。
在 TileLang 的生态上,目前已经有一些用户在使用了,例如微软的低精度大模型 BitNet 模型的核心量化算子是基于 TileLang 来开发,微软的 BitBLAS 也是完全基于 TileLang 。在国产芯片支持方面,算能 TPU 和昇腾 NPU 我们也都做了一些支持。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国